SQL食用笔记
提示
文章所指代SQL为SQL server 2008 R2
> 长文预警!!!建议按分支查看,记住Crtl+F哦
🗒数据库基础部分
- 常见有MySQL、SQL Server、Access、Oracle、Sybase等数据库系统。
5个系统数据库(由系统自动创建!)
- master 主数据库,存储了系统级别信息,极为重要!
- model 模板数据库
- msdb 代理服务器数据库
- tempdb 临时表(存储每次的查询结果,自动删除)
- resource 源数据库,只读且隐藏
数据库文件分类
- 主要数据文件
后缀.mdf- -存储服务器级信息- 次要数据文件
后缀.ndf- 事务日志文件
后缀.ldf- -用于定点数据库恢复数据库文件组
- 主文件组
Primary``默认- 用户定义文件组
一个数据文件只能属于一个文件组,事务文件不属于任何文件组!
E-R模型
- 三要素:实体,属性,联系
- 一般在
逻辑结构设计阶段将其转化为关系模式并规范化
模式
- 又称概念模式或逻辑模式
- 是数据库中全体数据的逻辑结构和特征的描述
- 一个数据库只有一个模式
- 体现了数据库的整体观
内模式
- 也称存储模式
- 它是数据的物理结构与存储方式的描述,即对外存数据组织的描述
- 一个数据库只有一个内模式
- 目的是减少数据冗余,实现共享,提高效率
外模式
- 也称为子模式或用户模式
- 一个数据库可以有多个
- 可以保证数据的安全性
参照完整性
- 表的外关键字必须是另一个表的主键的有效值
- 外键约束
foreign key实体完整性
- 保证每一行数据不重复
- 包含:
主键约束,唯一性约束,null约束
约束
- Check约束:限制一列或多列值的范围
- Default约束:在无值时赋予默认值
- Primary key约束:维持实体完整性,主键列值必须唯一
- Foreign key约束:建立参照完整性,主表主键列被参照的值不能被修改
- Unique约束:为一列或多列提供实体完整性,即两个行间的值不能重复
其他
- 数据库管理系统中最重要的部分是数据库
- 候选码中的属性可以有1个或多个
一些类型解释
| 对象 | 备注 |
|---|---|
| int | 取值范围:-231~231-1,长度为4个字节 |
| varchar | 可变长度字符 |
| smallint | 有符号的取值范围为:-32768——32767;无符号:0——65535,长度为2个字节 |
| tinyint | 0~255的整型数据,长度为1字节 |
探讨AB>CD
首先判断A与C,A的ASCII码为65,C为67。65>67==>false;其关系为||,当已存在false时将不再判断B>D,结果即为false
🗒数据库操作
创建与插入
数据库是最基础的东西,数据表与视图等都建立在你的数据库之上。
1 | Create database 数据库名 |
创建表
1 | Create table 表名 |
创建视图
1 | Create view 视图名 |
创建索引
聚集性索引
1
Create clustered index 索引名 on ...
非聚集性索引
1
Create noclustered index 索引名 on ...
唯一性索引
1
Create unique index 索引名 on ...
注. on后可跟多个列,即可在多个列创建索引 P.126
创建函数
1 | Create function 函数名(参数) |
- 声明函数:
1
2
3Declare @变量名 类型
set @变量名=值 --赋值一个变量
select @变量名=值 --可赋值多个变量
创建过程
1 | Create procedure 过程名 |
创建触发器
1 | Create trigger 触发器名 |
注. 详见下方T-SQL编程部分
创建登录名
以登录名创建用户
创建一个登录名可以登录该数据库而不是添加其他用户
插入
1 | Insert into 表名(列名) values(值) |
- 当每个列都有值插入时,可忽略
表名(列名)一句 - 可插入多行值,使用
,隔开每行值
SP_查看
查看数据库
1 | sp_helpdb 数据库名 |
查看数据表
1 | sp_help 表名 |
查看语句结构
1 | sp_helptext 名称 |
该语句大量应用于查看定义该过程,视图,触发器…的语句结构
查看依赖关系
1 | sp_depends 名称 |
该语句常用于查看视图、存储过程等所引用的其他对象
查看索引
1 | sp_helpindex 索引名 |
修改与更新
修改数据库
1 | Alter database 数据库名 |
修改索引
- 重新生成索引
1
Alter index 索引名称 on 索引基于的视图或表名 rebuild
- 禁用索引
1
Alter index 索引名称 on 索引基于的视图或表名 disable
修改存储过程
- 修改存储过程名称
- 修改存储过程名称
1
2Alter procedure 存储过程名称
......
修改视图
1 | Alter view 视图名称 |
修改子文件
添加服务器固定角色
DBCC
收缩数据库中的数据文件大小
1 | Dbcc shrinkdatabase(数据库名,收缩的百分比大小) |
收缩指定数据文件大小
1 | Dbcc shrinkfile(文件名,收缩的百分比大小) |
展示索引的统计信息
1 | Dbcc show_statistics ('数据库名.dbo[架构].表名','索引名') |
更新
更新表的记录
1 | Update 表名 SET 要更新的字段名='值' WHERE 条件; |
注. 在无where条件时将更新所有行!
删除与重命名
删除数据库
1 | Drop database 数据库名 |
删除表
1 | Drop table 表名 |
删除某表的某记录
1 | Delete from 表名 where 条件 |
注. 在无where条件时将删除所有记录,但表还存在。
删除视图
1 | Drop view 视图名 |
删除索引
1 | Drop index 表名.索引名 |
删除存储过程
1 | Drop procedure 存储过程名称 |
删除自定义函数
1 | Drop function 函数名称 |
删除触发器
添加登录名
删除用户
删除服务器固定角色
重命名
1 | Sp_rename 旧名称 新名称 |
查询
- 查询部分是涉及最多的内容,因此整体概述
1 | use 学生 |
查看一个表的内容
查看'学生表'
同样,该语句也可以去查看一个视图查看'View_学生视图'
上面的语句是完整的返回所有内容,我们可以加上判断条件:
1 | select 列名,第二个列名... from 表名 |
有时候我们想对表的内容再进行一个筛选,例如我们希望选择’性别为女的同学’,则就需要使用 where子句
where子句
1 | select * from 学生表 where 性别='女' |
- 但是我们会发现输出来的很多列有重复的值,我们只希望每个班只输出来一次,则可以用
Distinct来去掉重复的值Distinct 1
select distinct 班级 from 学生表
条件运算符
| 运算符分类 | 运算符 | 备注 |
|---|---|---|
| 比较运算 | >,>=,=,<=,<>,!=,!>,!< | 其中<>与!=均可表示不等于,其余的你应该知道的 |
| 范围运算 | between…and(包括界值),not between …and | 列的值是否在某个范围中 |
| 列表运算 | in,not in | 在/不在指定的列中 |
| 模糊匹配 | like,not like | 需要配合通配符,后面例中说明 |
| 空值判断 | is null,is not null | 是空/不是空 |
| 逻辑运算 | and,or,not | 和/或/非 |
我们可以在where后跟多个条件,使用运算符来连接他们
判断年龄小于18,性别为女且不是1班的同学
输出出生年月在2001-2002年间的同学姓名
1 | select 姓名 from 学生表 where 出生年月 between '2001-1-1' and '2002-12-31' |
输出学号在1001,1002,1003中的同学姓名
1 | select 姓名 from 学生表 where 学号 in('1001','1002','1003') |
如果法外狂徒张某犯事了,需要找出所有姓张的男生进行匹配,那么我们就需要进行模糊匹配:
匹配所有张姓
上面即涉及到了模糊匹配,其实模糊匹配仅是将where后面的条件的=换为了like,我们需要记住下面的通配符:
输出所有姓王(名字共两个字)缺考(成绩为空)的非1班的同学的姓名,成绩
1 | select 姓名,成绩 from 学生表 where 班级!='1班' and 姓名 like '王_' and 成绩 is null |
注意,其中一个_可以表示一个字符,可以多个使用,它们也可以匹配空格
集合函数
集合函数 描述 count() 统计元组,常用count(*)统计行数,返回包含空值的行数,但它不能与Distinct(去重复)一起使用 SUM() 一列数据的总和 (需要类型为数值)AVG() 一列数据的平均值 (需要类型为数值)MAX() 通俗易懂 MIN() 通俗易懂 当然还有时间函数
GetDate
2
3
4
month() --月
day() --日
getate() --获取现在的时间查询所有学生姓名并添加上查询的时间
其中查询日期列未在表内
我们可以看见,这种方式实现了两个功能,添加了一列和时间
- 其中也可以这么实现
墙裂推荐,as太爽了 1
select 姓名,getdate() as 查询日期 from 学生表
上面使用了as别名与时间函数,其中时间函数还可以用来取值
输出所有学生的出生年(单独的列)
year()
select的分组与排序
- 1.Asc 升序排列
默认 - 2.Desc 降序排列
对计算机课的学生的成绩按降序排列
Order by 1
select * from 学生 where 课程='计算机' order by 成绩 desc
降序必须写Desc,升序默认可忽略
使用它需要满足以下条件:
- 列名运用了集合函数(sum,avg等…)
- 未应用集合函数的列名必须包含在
group by子句中
统计男女各人数
group by 1
select 性别,count(*) as 男女人数 from 学生 group by 性别
- 我们对性别进行了分组,可以看见它没有使用集合函数,所以它必须包含在group by子句当中。也就是说,对什么进行分组,必须将它放到select后面查找一遍。
Having子句 它常与group by一起使用且只能与group by一起使用
- where后面不能使用集合函数,但having可以。它们的区别详见教程P95
查询每门课成绩都在70以上的学生学号
Group by 1
select 学号 from 课程 group by 学号 having min(成绩)>=70
即显示统计结果,又显示明细数据。了解即可 详见教程P96
多表连接查询
~基本的语句已结束,下面我们来点刺激的吧~
内连接 P99
连接多个表,并且可以将某些值的连接起来,以此来联系并利用多张表的数据。
将学生表与选课表连接起来,输出每个同学在两张表中的所有数据(用学号连接)
2
3
4
5
6
7
--笛卡尔乘积运算后再条件筛选
2. select 学生.*,选课.* from 学生 Inner join 选课 on 学生.学号=选课.学号
--使用inner join 子句三张表使用inner join 子句连接样式
2
3
4
join 选课 on 学生.学号=选课.学号
join 课程 on 课程.课程号=选课.课程号
where 课程名='文化欣赏'
内连接可能导致部分信息丢失
外连接 P.100
外连接有主次之分,不会有信息丢失,但仅适用于两个表
- 左外连接
将左表中所有数据行与右表每行匹配,JOIN左边的表为主表
- 右外连接
与左外连接类同,仅位置关系发生了变化。
- 完全外连接
结果集包含了两个连接表的所有行。
1 | select A.教师号,教师名,课程名 |
该处陈述较为模糊,详见教材P.101
自连接 P.101
自连接就是一个表的两个副本之间的内连接
即对一个表进行不同条件的连接查询
1 | select B.学号,B.姓名 |
子查询 P.102
在一个select语句中嵌套另一个select语句的where条件中使用
比较子查询
父查询与子查询使用比较运算符连接,此处子查询的结果只能返回一个值
1 | select 学号,成绩 from 选课 |
IN子查询
父查询与子查询使用in/not in连接,判断该值是否在子查询返回的集合中
1 | select 姓名 from 学生 |
批量子查询
- any谓词
与子查询的每一项比较,一个为true,即为true
- all谓词
与子查询的每一项比较,全部为true,即为true
EXISTS子查询 P.105
即为子查询判断语句,子查询返回为真即true,开始执行语句。
1 | go |
视图与索引
视图常用的操作
- 筛选表的行
- 防止用户访问敏感数据
- 将多个物理表抽象为一个逻辑数据表
优点
- 简化用户操作
- 使用户能从多个角度看待同一数据
- 对数据库提供一定的数据逻辑独立性
- 对机密数据提供一定的保护
- 可以重新组织数据
其他
- 当使用
Alter修改视图时原权限不会变化,当图形界面修改时权限需要重设。- 视图每次只能对一个基表中的数据进行更新
其他
- 每个表只能有一个聚集索引,在没有索引时主键会自动创建该索引
- 为一个表创建的索引默认为非聚集性索引
- 聚集索引与非聚集性索引都可以是唯一性索引
- 每个表最多创建
249个非聚集索引- 一个索引宽度不能超过
900字节- 列类型为:
text,ntext,image,bit的列不能创建索引- 一个索引最多包含16个列
- 创建唯一性索引时应保证该列没有重复数据且两个及以上空值
- 聚集性索引可以对表进行物理排序
T-SQL编程部分
基础部分
批处理
2
3
批处理语句
go
即两个go之间语句为一个整体执行注释
2
3
4
5
6
/*
多行注释
多行注释
*/
注释即为不执行的语句,写给人看的常变量
局部变量
- 以一个@开头
- 一定范围有效,批处理结束该变量便结束
- 使用前应先使用
Declare语句声明 见创建与查询部分
全局变量
- 全局变量以@@开头
- 用户不能建立,修改全局变量
- @@error 返回错误的编号
常见全局变量见P.137
运算符
| 类型 | 符号 |
|---|---|
| 算术运算符 | +,-,*,/,%(取模) |
| 赋值运算符 | = |
| 字符串连接 | + |
| 位运算符 | &(与),︱(位或),^(位异或) |
| 一元运算符 | +(正),-(负),~(位非) |
| 比较运算符 | <>(不等于),!=(不等于),>,<,=,>=,<= |
| 逻辑运算符 | and,or,not,between…and(范围,包括界值),in,like,is null,exists(存在) |
SQL语言
- DCL控制语言
- DML操作语言
- DDL定义语言
数学函数
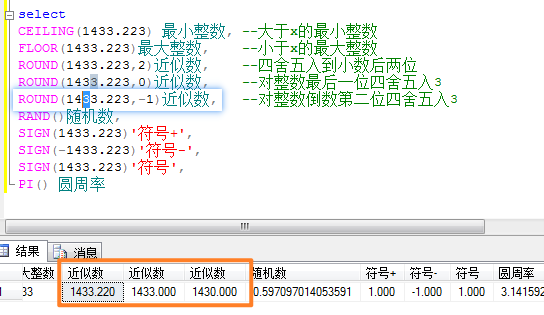
注意3个近似数的取值
其他
- 临时表:一个#开头
- 全局临时表:两个##开头
流程控制
Begin…end
2
3
4
5
6
{
语句
这些语句将作为一组执行
}
endIF_else
2
3
4
5
6
7
8
{
布尔返回为真时执行
}
else
{
布尔返回为假时执行
}
- 当布尔表达式为select语句时应用()包围起来
case表达式
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
when 旧值1 then 新的值1
when 旧值2 then 新的值2
when 旧值n then 新的值n
end
```
- 例如将课程号的1,2,3,4替换为具体名称
```sql
select 学号,课程名=case 课程号
when 1 then '文学欣赏'
when 2 then '中国历史'
when 3 then '视频编辑'
when 4 then '音乐欣赏'
else 'UNknow'
end,成绩
from 选课中断流程
- 中断本次循环:
Continue- 直接结束整个循环:
Break从1加到100
2
3
4
5
6
7
8
9
10
select @sum=0,@i=1
while @i<=100
begin
set @sum=@sum+@i
set @i=@i+1
end
print @sum创建自定义标量函数
2
3
4
5
6
7
returns 返回的数据类型
as
begin
函数内容
return 表达式
end
调用:
1 | set @变量=owner.用户自定义函数名称(参数) |
- 例如创建一个输入课程号查看平均分的函数
1
2
3
4
5
6
7
8
9
10
11
12
13create function avera(@cno varchar(12))
returns float
as
begin
declare @aver float
select @aver=(select AVG(成绩)
from 选课
where 课程号=@cno
group by 课程号)
return @aver
end
/*输出课程号为2的平均分*/
print convert(char(6),dbo.avera(2))
存储过程与触发器
存储过程
基础
- 它是一个在SQL中预先编排好的
T-SQL语句 - 执行速度快
- 减少了网络通信量
- 规范了程序设计
- 可以提高程序的安全性
分类
- 本地存储过程
用户自行创建并存储 - 临时存储过程
分为局部临时存储(#)与全局临时存储(##) - 远程存储过程
位于远程服务器的存储过程 - 拓展存储过程
使用其他语言创建的外部存储过程,在SQL中运行
创建不带参数的存储过程
1 | go |
- 例如创建不带参数的cs_teacher过程,返回教师表中工号为002的教师信息
1
2
3
4
5
6
7go
Create Procedure cs_teacher
AS
Select * from 教师 where 工号='002'
go
/*执行函数*/
EXEC cs_teacher
创建带参数的存储过程
2
3
4
5
6
7
8
9
Create Procedure 过程名
@定义参数变量 类型
AS
执行的语句
GO
/*其中调用过程则需要带参*/
EXEC 过程名 @参数=值
- 例如创建一个输入教师工号查询信息的过程
1
2
3
4
5
6
7
8GO
Create Procedure new_teacher
@工号 varchar(5)
AS
Select * from 教师 where 工号=@工号
GO
/*执行*/
EXEC new_teacher @工号='002'
带参的过程可以按照位置传递参数,在带多个参数时需要注意位置顺序
带输入输出参数的存储过程
2
3
4
5
6
7
8
9
10
11
Create Procedure 过程名
@定义参数变量 类型,@ 定义输出变量 类型 Output
AS
执行的语句
GO
/*其中调用过程则需要带参且先定义一个局部变量存储输出*/
Declare @局部变量 类型
EXEC 过程名 @参数=值 ,@局部变量 output
select @局部变量
- 例如统计年龄为40的教师的人数
1
2
3
4
5
6
7
8
9
10GO
Create Procedure age
@输入年龄 int,@print_age int Output
AS
select @print_age=count(*) from 教师 where 年龄=@输入年龄
GO
/*调用过程*/
Declare @abc int
EXEC age 40 ,@print_age output --40采用位置传递
select @abc
修改存储过程
将new_teacher修改为输入工号查性别并对语句加密
1
2
3
4
5
6
7
8
9
GO
Alter Procedure new_teacher
@工号 varchar(5)
with encryption
AS
Select 性别 from 教师 where 工号=@工号
GO
/*执行*/
EXEC new_teacher @工号='002'
1 | GO |
触发器
基础
- 实现完整性约束
- 自定义提示错误信息
- 可以对表进行联级更改
- 维护、规范化数据
类型
After触发器:在操作执行后触发Instead of触发器:在操作执行之前触发分类
Insert触发器:插入时触发Update触发器:更新时触发Delete触发器:删除时触发创建触发器
在数据插入后提示”成功插入数据!”
2
3
4
5
6
Create trigger 触发器名称 on 表名
After(类型) insert(类别)
As
print '成功插入数据!'
Go
Update与Delete同理,我们只需要注意触发器的前后与3种类别即可
禁用与启用
- 禁用触发器:
Disabletrigger触发器名称- 启用触发器:
Enabletrigger触发器名称
禁用与启用全部触发器只需要在触发器名称后面加上All即可
其他
raiserror:抛出错误
raiserror(‘你无权限执行本操作’,10,1)
Rollback:回滚操作(撤销)
写在最后
此文档写于期末考试之际,未涉及太多相关知识。我们将在工作与生活中再次与它交锋!





![基于GPS的坐标路径分析系统[待更新]](https://pic.imgdb.cn/item/63bd61cbbe43e0d30e088c6f.png)