基于Selenium实现python浏览器自动化
一个活动非得让我拉几百人个人填表单,无奈。
找了一半天脚本找不到,想通过油猴来完成这个浏览器操作。但是却发现表单限制,记录浏览器记录,只能填一次:-)
于是决定通过python的Selenium库来实现浏览器操作,同时模拟出500个用户信息。
环境搭建
环境已配置好请忽略
关于Selenium库的安装及环境配置请参照Python Selenium库的使用文章
需要注意一下几点坑了我好久:
下载Selenium驱动程序时请在:这里下载与你
Chromium内核版本一致的驱动程序。- 若你是其他浏览器或者系统,请参照官方Github仓库,Selenium官网。
下载的驱动程序包需要放置在你的浏览器exe文件同一目录下
配置环境变量时名称应填
chromedriver,值应填写到该目录下。- 也可python中指定
chromedriver路径,只有当py中没有指定路径时才会去环境变量中去搜Chromium的路径。
- 也可python中指定
在配置完成后python执行:
1 | from selenium import webdriver |
不出意外的话会打开一个新窗口,打开我的博客页面。
1 | from selenium import webdriver |
不出意外的话会打开一个新浏览器窗口,并且打开百度搜索”三体”。
到这里一切正常就代表成功搭建了环境。
执行操作
打开页面,使用开发者工具定位到选项标签。复制Xpath下来。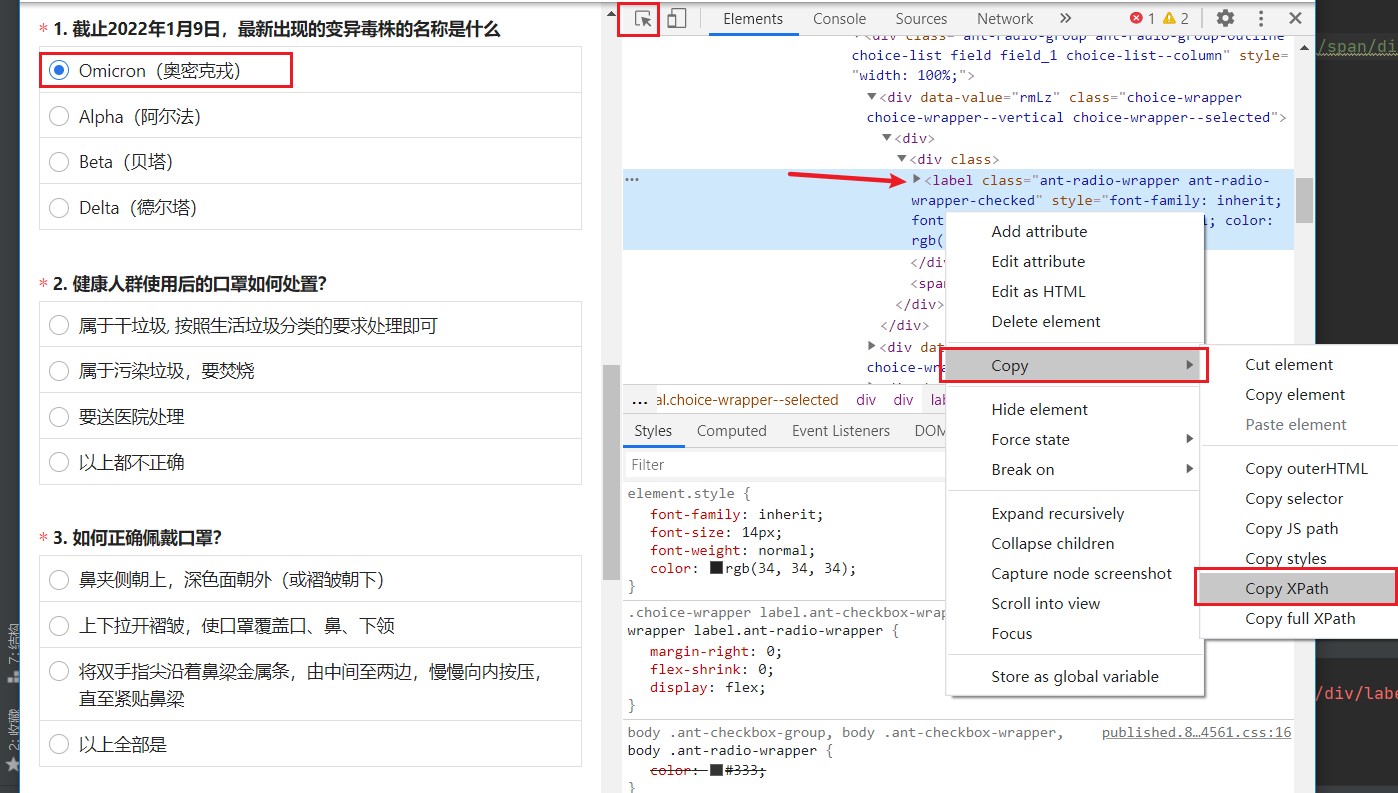
selenium有多种定位的方法,详情见CDSDN博客。
一般我们使用的就是find_element_by_xpath或者find_element_by_name,find_element_by_id
即通过路径表达式,name和id
在这里我们使用xpath找到标签,进行点击操作
1 | import time |
运行代码,不出意外的话就会自动点击了
不出意外的话就会出意外
有时候你会发现get出了页面,但没有点击操作。这个时候或许可以:
- 检查xpath是否正确,可以尝试定位到该元素的父标签上
- chromedriver驱动程序版本是否与你内核版本一致。
- 尝试x+1次
有5道题目,我们对其进行5次点击操作
1 | from selenium import webdriver |
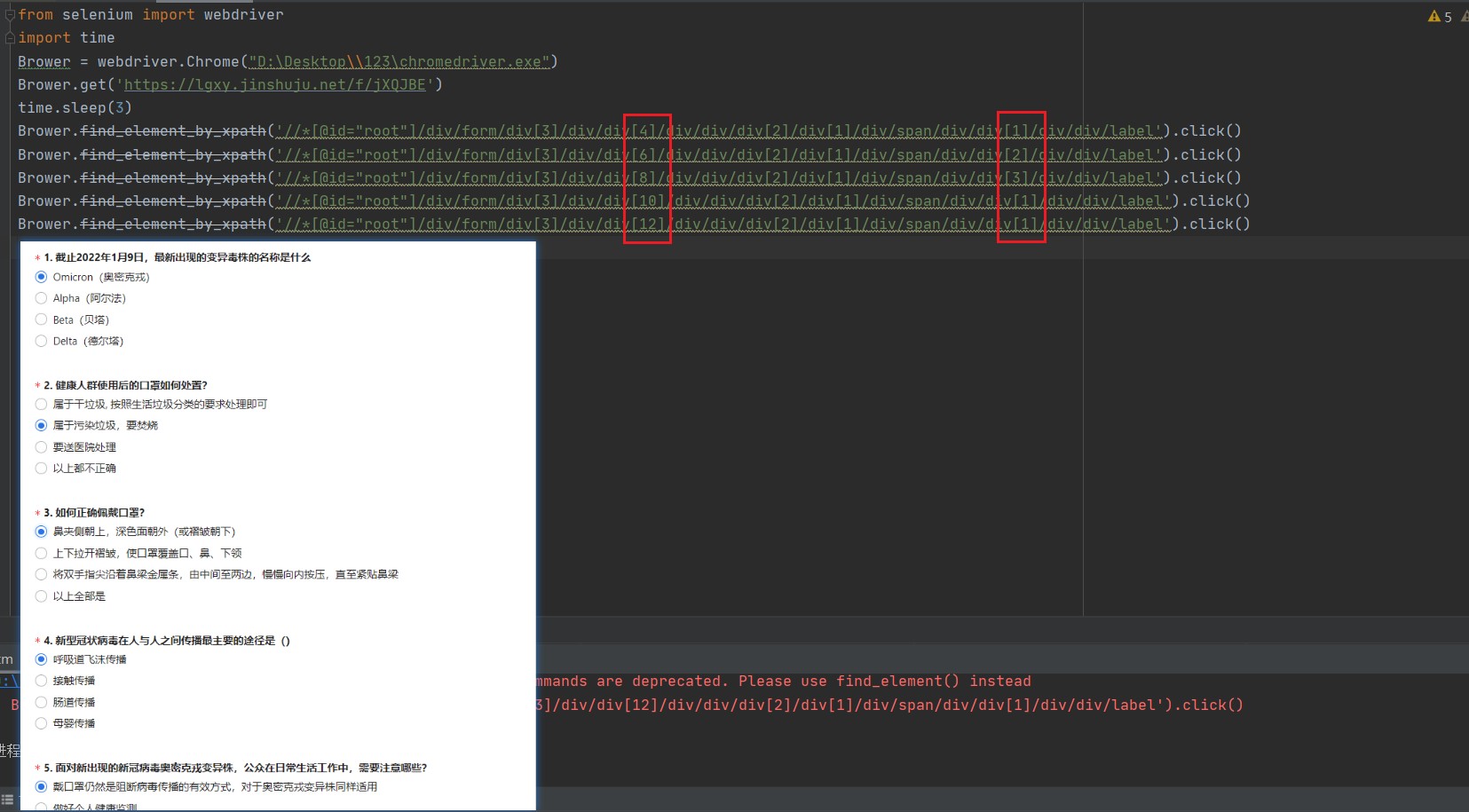
可以看见其中的[]内容控制了选项与题目。不出意外的话你的5道题目应该已经选好了。
使用name定位点击下一页
1 | Brower.find_element_by_class_name('published-form__footer').click() |
填充文本
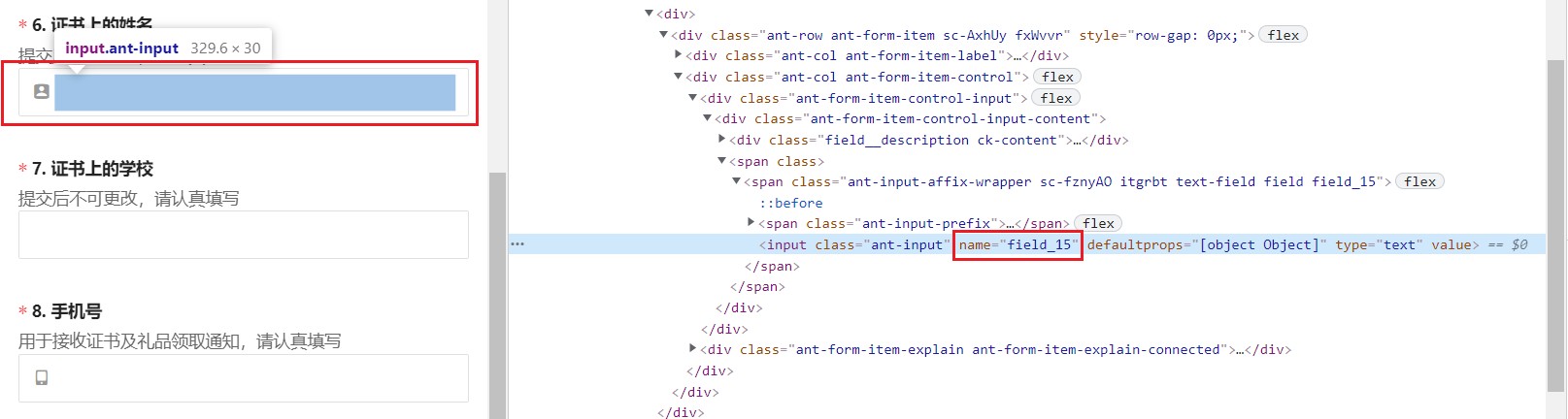
在input中需要我们填写姓名,学校,电话等内容
这里使用name获取到input后send_keys填充内容
1 | Brower.find_element_by_name('field_16').send_keys("霍格沃茨") |
然后我们用点击下一页的方法点击提交即可
关闭浏览器
1 | Brower.close() |
最后贴一下我简单的代码
1 | import time |

此为学习自动化操作笔记,完成一些不重要的指标要求。谴责恶意刷题行为!