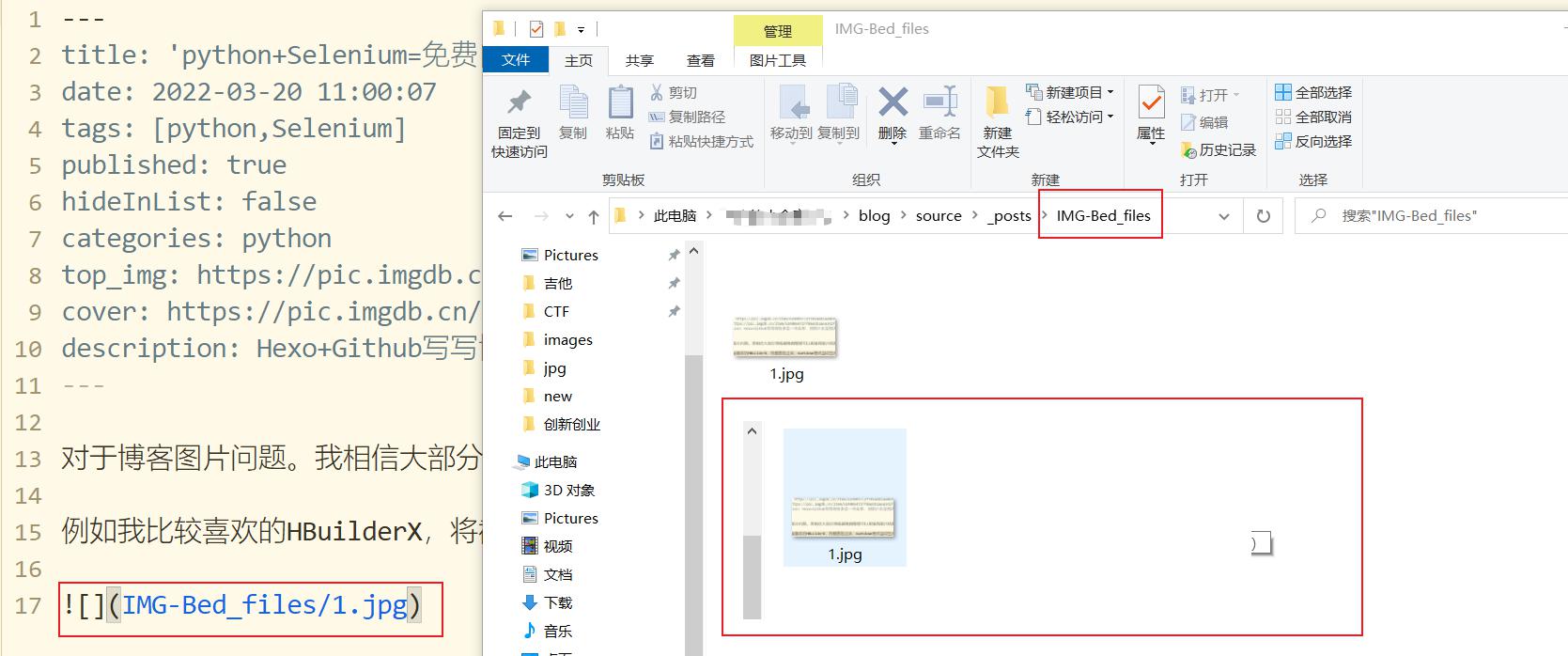
前世今生 对于博客图片问题。我相信大部分博客编辑器都是可以直接将图片粘贴过去。生成一个本地文件夹来存储这些文件。
例如我比较喜欢的HBuilderX,将截图贴过来,markdown格式自动生成语句,本地创建文件夹。
我们在本地可以很愉快的查看我们的预览效果。但是,推送到Github上就出现了奇奇怪怪的问题。一方面是图片过多,上传速度过慢,且由于一些科学上网的原因,很多时候会上传失败。
另外是访问速度不是很舒服,这不是优雅的图片解决方案。
图床,尤其是大厂图床。CDN加速,无流量限制,随用随修改,这才是我们理想的图片解决方案。
但是,优雅的解决方案往往伴随着需要钞能力的加持。我们租用服务器,搭建平台,建设API……
我们大可不必重新建设轮子,在网络上有非常多的免费图床提供。
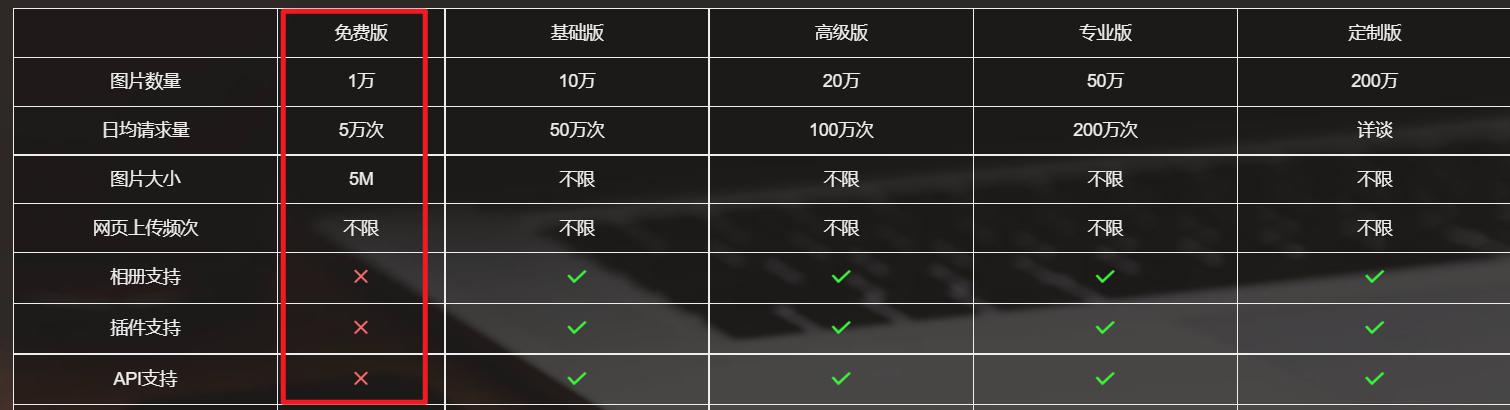
这些免费图床实现了我们免费白嫖图床的想法。但实际使用检验,很难有免费图床可以不登陆 ,不删除 ,不限流 ,不限量 ,不跑路 ……
我很喜欢使用路过图床 ,它可以很好的解决上述问题。稳如老狗。
但又出现了一个新的问题。在游客中上传图片只能一次上传一张 。作为白嫖客,我完全理解。但这样使用一张图片就需要手动上传一次实在不优雅。
更优雅的解决方案当然是读取本地markdown文档和相关文件夹,自动上传图片获得Url链接,并将其替换md文档内链接。
但正如上述,优雅往往需要钞能力加持。提供API接口的图床很多,但免费的寥寥无几。于是,我们需要使用一个次优雅的解决方案。
我们使用Python+Selenium库来实现python操作浏览器。
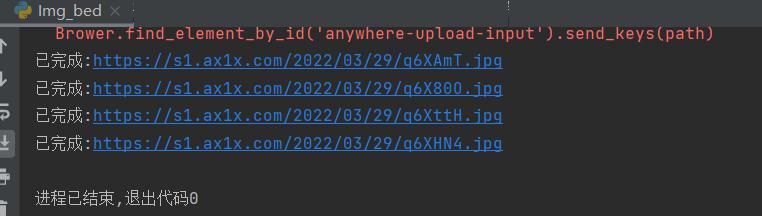
Python进行对本地文件夹与markdown文档读取。循环提交文件夹内的图片,拿到上传成功的Url链接,替换掉md文档内原路径链接。
理论存在,实践开始 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import osimport reimport timefrom selenium import webdriverdef post_img (path ): Brower = webdriver.Chrome("E:\百分浏览器\chromedriver.exe" ) Brower.get('https://imgtu.com/' ) time.sleep(3 ) Brower.find_element_by_id('anywhere-upload-input' ).send_keys(path) time.sleep(2 ) button='document.querySelector("#anywhere-upload-submit > div:nth-child(1) > button").click()' Brower.execute_script(button) time.sleep(6 ) html=Brower.page_source jpg=re.findall(r'image_src" href="(.+?)">' ,html) Brower.close() print ("已完成:%s" %jpg[0 ]) return jpg[0 ] def alter (file,old_str,new_str ): with open (file, "r" , encoding="utf-8" ) as f1,open ("%s.bak" % file, "w" , encoding="utf-8" ) as f2: for line in f1: if old_str in line: line = line.replace(old_str, new_str) f2.write(line) os.remove(file) os.rename("%s.bak" % file, file) folder_name = os.listdir("G:\\blog\source\_posts2\OCR_img_files" ) for i in range (len (folder_name)): data_name = "OCR_img_files/" + folder_name[i] post_path = "G:\\blog\source\_posts2\\" +data_name.replace("/" , "\\" ) alter("G:\\blog\source\_posts2\OCR_img.md" , data_name, post_img(post_path))
其中文件路径需要仔细注意。
对Selenium存在疑问可以去”百度+必应”联合大学查找办法。大概流程可以参考我的博客文章基于Selenium实现python浏览器自动化





![基于GPS的坐标路径分析系统[待更新]](https://pic.imgdb.cn/item/63bd61cbbe43e0d30e088c6f.png)