简单处理一下图片
很烦截图诶,老是让我去查谁没交。名字在图片上,吸取上次的经验,我把“查查谁没交截图”做成了全自动😅
顺便把剪切图片这种烦人的工作也加了上去😑
大概的思路就是将所有图片放在一个文件夹下,对这个文件夹下所有图片进行一个处理。
先进行OCR文字识别,把名字识别出来,然后用花名册对它进行遍历查找。
再顺便写了个批量剪切图片,就可以把证件照啥的一下全剪成200x200啥的。多是一件美事。
OCR识别
对于OCR识别,大致有两种方式。一是在线识别操作,二是本地离线模型包,离线识别。
免费在线识别有很多,随便一搜就有很多。但是无一例外,都是一张一张上传识别,不符合我们设计程序的思路。
大厂的OCR技术倒是有API接口,百度,腾讯,阿里……但无一例外,免费次数有限,而且我们操作的某些图片不太适合进行上传。
所以在这里,我选择了开源的PaddleOCR项目来作为轮子
同样,开源OCR项目也有很多。但Paddle项目的文档很全,且包很小,轻量CPU仅9MB。
Github地址:https://github.com/PaddlePaddle/PaddleOCR
Gitee地址:https://gitee.com/paddlepaddle/PaddleOCR
官网地址:https://www.paddlepaddle.org.cn/
🍕在python中安装PaddleOCR
从百度源下载cpu版本paddle库
1 | python -m pip install paddlepaddle==2.2.0 -i https://mirror.baidu.com/pypi/simpl |
安装shapely
在https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely去找到shapely的whl包进行安装
在这里需要注意,你该如何选择对应的whl包?
执行命令:
1 | pip debug --verbose |
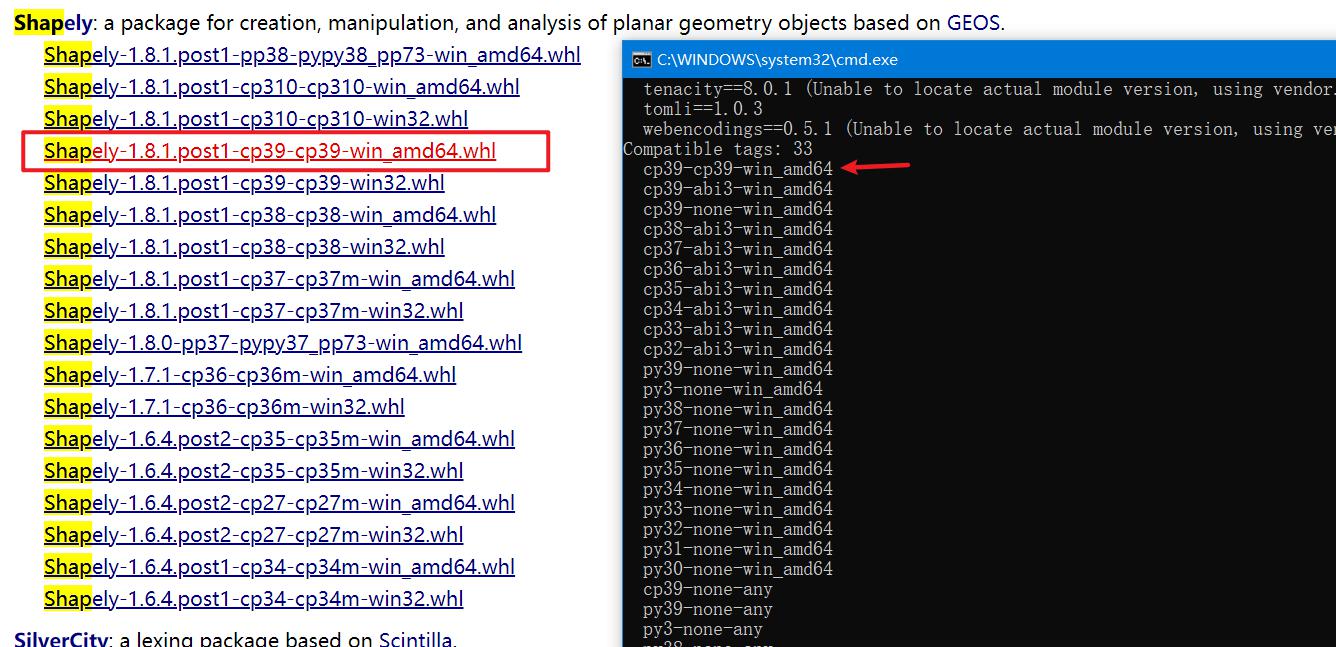
查看当前你支持的whl包,去下载对应的包。
下载后将whl包放在工程目录下(其他地方cd过去也行),执行:
1 | pip install xxxxxxxx.whl |
如果遇到错误,很可能是不支持的whl包。你下载了
安装其他依赖
在项目下新建requirements.txt文件,里面填写官方文档内的内容
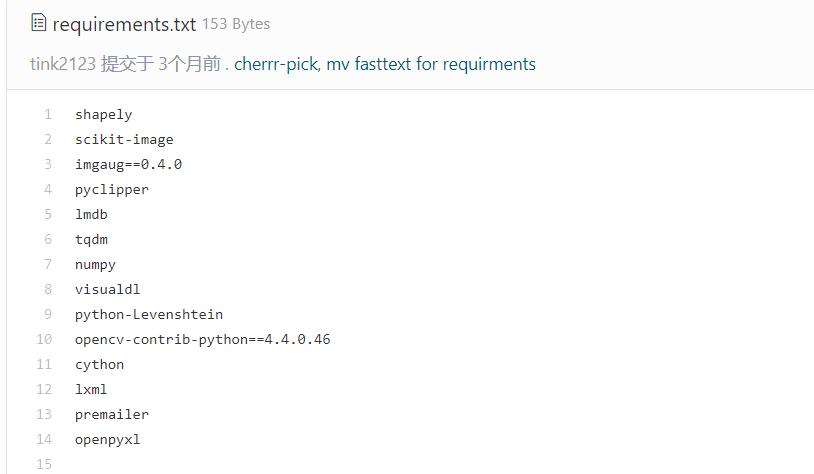
然后在该目录下执行:
1 | pip3 install -r requirements.txt |
最后安装PaddleOCR
执行命令:
1 | pip install "paddleocr>=2.2.0" |
好了,不出意外的话你已经安装好了所有的拓展包.
不出意外的话就要出意外
以下是我遇到的部分问题
报错: error: Microsoft Visual C++ 14.0 is required.
安装Levenshtein
同样进入https://www.lfd.uci.edu/~gohlke/pythonlibs/#python-levenshtein
找到对应的whl包下载,pip安装它。
这里有详细文档
报错: ‘NoneType’ object has no attribute ‘array_interface‘
极有可能是因为你的文件路径包含了中文,python的安装路径也是一样,不能包含中文。
在期间我还遇到了很多奇奇怪怪的错误,大部分都可以在百度-必应联合大学下找到答案。
下载cpu解析模型包
如果不需要大型模型包,可以忽略本步骤。paddleocr可以自行检测是否有模型,如果没有就下载轻量级模型包。
🍕python程序运行
可以参照此文档检验自己的配置是否正确
我直接贴我处理完后的代码
1 | # -*- coding: utf-8 -*- |
在这里我为了配合其他代码块简洁。将OCR识别区域写为了一个函数
需要传入2个参数,一个是
部分代码解释
- 直接传入中文名称会有奇奇怪怪的问题,在程序开始部分对其重命名为test。在识别成功会被重命名,识别失败会被重命名为原名称。
- 代码中直接判断了百家姓规则,将符合规则的字符串作为姓名把图片重命名。
- 其中注释掉了展示版面分析部分,即第81,82行。

OCR识别部分完结🍕
OCR识别部分完结🍕
图片剪切
1 | # -*- coding: utf-8 -*- |
使用了PIL库直接操作了图片,没有什么特别的地方。
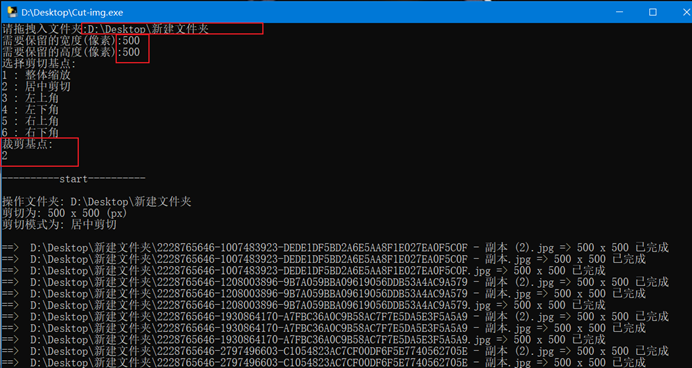
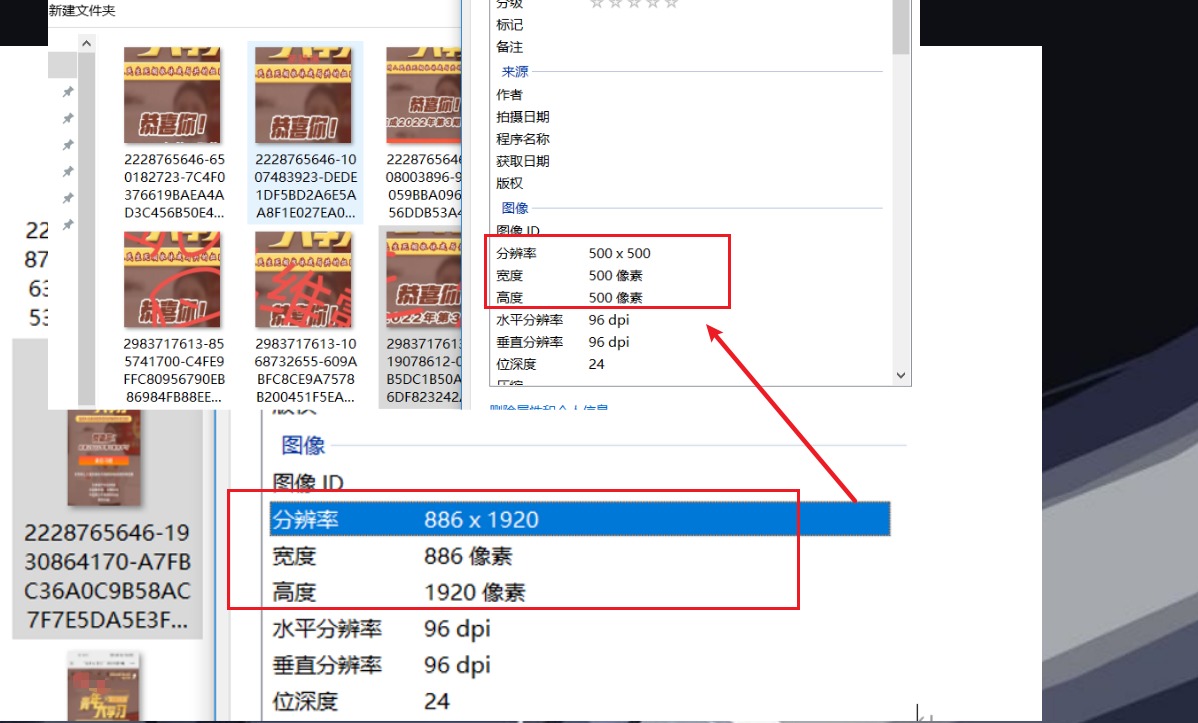
主要是剪切的坐标系需要注意,是从左上角开始。
同样写为了一个函数,需要传入(file_in, width, height, value),分别是:图片绝对路径,保留的宽度,高度,基点位置。
单文件版本见我的吾爱贴子
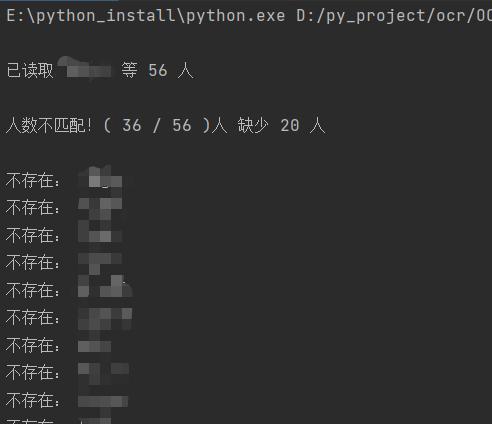
文件查缺少
1 | import re |
传入2个参数,一个是花名册.txt,将名单每行一个存入txt文件。另一个是需要遍历查找的文件夹路径。
自动查找缺少谁。
1 | without("花名册.txt","D:\Desktop\\test2\\") |
遍历文件夹*
上述前俩功能,都需要去处理文件夹下所有图片。
所以此功能是它们的驱动。
1 | import re |
在此函数的驱动下,OCR识别与cut_picture俩个函数功能只需要传入一个即可。
1
2
3
find_folder("D:\Desktop\hh"+"\\","ocr",0,0,0) # OCR识别,传入文件夹路径即可
find_folder("D:\Desktop\\02-副本\\","cut",200,500,"middle") # Cut图片,传入文件夹路径,宽,高,基点位置
1 | find_folder("D:\Desktop\hh"+"\\","ocr",0,0,0) # OCR识别,传入文件夹路径即可 |
Ui绘制
很多朋友说程序黑乎乎的Dos窗口很丑。于是我用PYQT5画了一个简单的Ui界面。
但,还没将他们关联好。
未完待续…



![基于GPS的坐标路径分析系统[待更新]](https://pic.imgdb.cn/item/63bd61cbbe43e0d30e088c6f.png)